The first time I came across smoothing with the Savitzky-Golay method was during my chemometrics class at university analyzing spectroscopy data using chemoetric methods. And indeed, the Savitzky-Golay method seems to have quite some awareness among spectroscopist, probably because Savitzky and Golay also worked in this field and referred to spectroscopy in their paper in 1964. The Savitzky-Golay method seems like one of those methods — similar to the moving average — where a sliding window of defined size is slid over the data and each time the smoothed version of the point  is calculated by averaging all data points inside the current window. In contrast to the moving average, the Savitzky-Golay method applies a sort of weighted average instead. But there is more to it as we shall see in this blog post.
is calculated by averaging all data points inside the current window. In contrast to the moving average, the Savitzky-Golay method applies a sort of weighted average instead. But there is more to it as we shall see in this blog post.
![\[\hat{y}_k = \frac{\sum_{i=k-m}^{k+m}c_i y_i}{\sum_{i=k-m}^{k+m}c_i}\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-07c2ca6695e7884819ecb8488879b02e_l3.png "Rendered by QuickLaTeX.com")
The  ‘s are the weights and denote the Savitzky-Golay coefficients. These are tabulated for various window sizes
‘s are the weights and denote the Savitzky-Golay coefficients. These are tabulated for various window sizes  (an excerpt of such a table is shown below).
(an excerpt of such a table is shown below).
| Window size = 5 | Window size = 7 | Window size = 9 | |
|---|---|---|---|
 | -21 | ||
 | -2 | 14 | |
 | -3 | 3 | 39 |
 | 12 | 6 | 54 |
 | 17 | 7 | 59 |
 | 12 | 6 | 54 |
 | -3 | 3 | 39 |
 | -2 | 14 | |
 | -21 |
It is common practice to use generalized data point indices in these tables, i.e. the central point of the sliding window has the index 0, while its direct left neighbour gets index -1 and its direct right neighbour +1 etc.
E.g. for a window size of 5 the 3rd data point of the smoothed signal is calculated by:
![\[\hat{y}_3 = \frac{\sum_{i=3-2}^{3+2}c_i y_i}{\sum_{i=3-2}^{3+2}c_i} = \frac{-3y_1 + 12y_2 + 17y_3 + 12y_4 - 3y_5}{35}\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-309c2ab3897c7c2c8c4efaf7a4f6304f_l3.png "Rendered by QuickLaTeX.com")
Then the sliding window is shifted one data point index upwards with  as the new center and the calculation is repeated with the new 5 data points inside that new window. And so on. This whole process can mathematically be expressed as a convolution:
as the new center and the calculation is repeated with the new 5 data points inside that new window. And so on. This whole process can mathematically be expressed as a convolution:
![\[\hat{y} = C \otimes y\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-68dec104039c1348c56c00bfec2bfe69_l3.png "Rendered by QuickLaTeX.com")
where  denotes the original signal and
denotes the original signal and  denotes the convolution kernel, i.e. the vector of filter coefficients.
denotes the convolution kernel, i.e. the vector of filter coefficients.
Boundary points (1, 2 and N-1, N for a window size of 5) must be treated differently as they do not have enough neighbouring data poinst left and right, respectively. Without digging too deep: one approach is to use the 2m+1 neighbourhood closest to the boundary point and fit these with a polynomial of appropriate size and estimate the boundary ordinate from the polynomial. Another approach is to use dedicated weight coefficients for the boundary points as described by Gorry in 1990.
Interestingly, when plotting the ‘s from the table above in a chart, you will realize that they form a parabola. Thus, the Savitzky-Golay is similar to the moving average but instead of a uniform weighting of data points inside the sliding window, the Savitky-Golay method applies a parabolic, or more general, a polynomial weighting.
The original paper by Savitzky and Golay in 1964 is very informative as they show that the convolutional approach with the coefficients naturally derives from fitting a polynomial  to a general sliding window with data points
to a general sliding window with data points  :
:
![\[p(n) = \sum_{k=0}^{N} a_k n^k = a_0 + a_1 n + a_2 n^2 + a_3 n^3 + \dots\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-b6b9d3d0128535cc9d7f8a1b44c33194_l3.png "Rendered by QuickLaTeX.com")
and estimating the center point  of that interval from the polynomial approximation at that position. At the end of this blog post I will sketch the derivation for the math-affine readers.
of that interval from the polynomial approximation at that position. At the end of this blog post I will sketch the derivation for the math-affine readers.
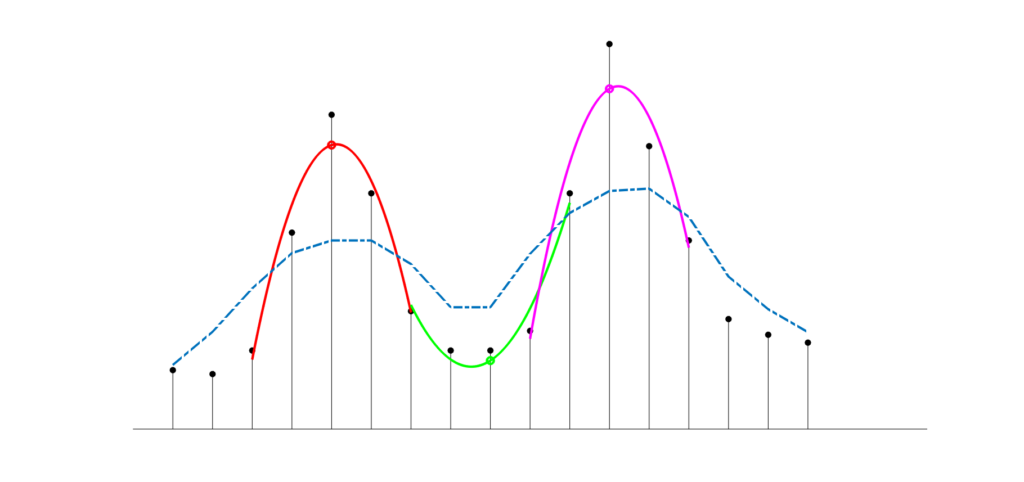
The following chart demonstrates the polynomial fitting for a discrete signal (black dots) with two peaks, one with a maximum at index 5 and another one with a maximum at index 12 and a valley in betwen the peaks. Examplarily, three sliding windows of size 5 were fitted each with a quadratic polynomial (red, green and magenta lines) and the center points (denoting the smoothed signal) are highlighted by circles of the same color. For reference, I added a moving average line (dash-dotted blue line) smoothed on the same window size, demonstrating that the Savitzky-Golay preserves the peak shape reasonably well while the moving average smoothes much coarser.
The advantage of the convolutions over the polynomial fitting approach is that the convolution approach is faster as it does not require to fit new polynomial coefficients to each sliding window but applies fixed Savitzky-Golay coefficients depending only on the sliding window width and the degree of the polynomial.
Another nice thing about the Savitzky-Golay method is its use for calculating derivatives of signals. Noisy signals must typically be smoothed ahead of taking their derivative. In these cases it is a two-step process: smooth first, then take the derivative. With Savitzky-Golay you can skip the first step as a dedicated set of SG-coefficients applies both at the same time: smoothing and derivation.
In the following I summarize some core features of smooting or derivating with the Savitzky-Golay filter:
Smoothing
- Because it fits a polynomial (usually of degree 2, 3, or 4) rather than a straight line, it is exceptionally good at preserving the height, width, and shape of spectral peaks while reducing high-frequency noise.
- The degree of smoothing depends on the window size (larger windows = smoother data) and the polynomial order (higher order = better feature preservation but less noise reduction).
Differentiation
- One of the most powerful features of the SG filter is its ability to calculate derivatives directly from the smoothing process.
- Standard finite-difference methods amplify noise significantly. SG differentiation acts as a “differentiator-smoother,” providing a much cleaner derivative signal.
- In spectroscopy, the second derivative is frequently used to resolve overlapping peaks; SG allows for this without losing the underlying signal structure.
A note of caution: The SG filter can be a great tool but when smoothing signals of high variability (e.g. different Peaks with different widths) a single parameter combination of window size and polynomial degree might be inappropriate. In fact, this is still an area of research on how to deal with these kinds of situations. Techniques like adaptive SG smoothing have been developed for this purpose.
I provide an Excel file (on our Software page) that contains the custom SGOLAYFILT function that can smooth or differentiate a signal based on the Savitzky-Golay method.
For those interested in the maths
In this section I’ll give a brief and hopefully more appealing derivation of the Savitzk-Golay coefficients than in their own paper. We begin by considering sample points  centered at
centered at  . We fit a polynomial
. We fit a polynomial  to the underlying data:
to the underlying data:  in a least-square sense, i.e. by minimizing the sum-of-squared error (SSE) between the data points and their polynomial correspondents wrt the polynomial coefficients
in a least-square sense, i.e. by minimizing the sum-of-squared error (SSE) between the data points and their polynomial correspondents wrt the polynomial coefficients  :
:
![\[\min_{a_0,\dots, a_N} \sum_{n=-M}^{M}\left(\sum_{k=0}^{N} a_k n^k - y_n\right)^2\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-3c008bd6d1849f3685e78e61c6e3c8e7_l3.png "Rendered by QuickLaTeX.com")
To keep the notation simple, we’ll use the following vector/matrix notation instead:
![\[\min_{a_0,\dots, a_N} \left(\mathbf{\hat{y}} - \mathbf{y}\right)^T \left(\mathbf{\hat{y}} - \mathbf{y}\right)\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-a7bffc48ebb304a05478b82f64918d60_l3.png "Rendered by QuickLaTeX.com")
where ![\mathbf{y} = \left[y_{-M}, \dots, y_0, \dots, y_M \right]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-1344193d726c6888d1214682e78b5bd4_l3.png "Rendered by QuickLaTeX.com") and
and  , with
, with  being the so-called Vandermonde matrix, with entries:
being the so-called Vandermonde matrix, with entries:
![\[\mathbf{J} = \left[\mathbf{j}_0, \mathbf{j}_1, \dots, \mathbf{j}_N \right]\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-ab61cdb99f7cda63b5106e27cdbc5b57_l3.png "Rendered by QuickLaTeX.com")
where  is a column vector (with
is a column vector (with  ranging from
ranging from  to
to  ) and
) and  being the the polynomial coefficients from above. For example
being the the polynomial coefficients from above. For example  is a column vector of ones (
is a column vector of ones ( ),
),  a column vector of
a column vector of ![[-M, \dots, 0, \dots, M]^T](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-e24023284874d0ac0fec7c9ade2cd185_l3.png "Rendered by QuickLaTeX.com") (for
(for  ),
),  a column vector of
a column vector of ![[M^2, \dots, 0, \dots, M^2]^T](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-5a72df6361d3f4a36d10a7299f1700e6_l3.png "Rendered by QuickLaTeX.com") (for
(for  ) and so on.
) and so on.
Plugging into the expression for the sum-of-squared error we re-formulate the minimization problem as follows:
![\[\min_{a_0,\dots, a_N} \left(\mathbf{J}\mathbf{a} - \mathbf{y}\right)^T \left(\mathbf{J}\mathbf{a} - \mathbf{y}\right)\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-fa81c3dba05f2d2624b86935cfe4a415_l3.png "Rendered by QuickLaTeX.com")
From the above equation we can solve for the polynomial coefficients using matrix algebra (e.g. see our blog post on weighted regression):
![\[\mathbf{a} = \left(\mathbf{J}^T\mathbf{J}\right)^{-1} \mathbf{J}^T \mathbf{y}\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-db5cb2fbb2330fe93aa1f95c9c5787ae_l3.png "Rendered by QuickLaTeX.com")
From the fact that our model is linear in its coefficients we can express the smoothed signal by:
![\[\mathbf{\hat{y}} = \mathbf{J} \mathbf{a} = \mathbf{J} \left(\mathbf{J}^T\mathbf{J}\right)^{-1} \mathbf{J}^T \mathbf{y}\]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-3966e4c670472ef3311c264c013b080c_l3.png "Rendered by QuickLaTeX.com")
The matrix  has size
has size  and is often called the hat matrix. It is interesting to note that the entries in
and is often called the hat matrix. It is interesting to note that the entries in  are independent of the samples and only depend on the length of the sliding window and on the polynomial order chosen. By the last equation we approximate each point in the window
are independent of the samples and only depend on the length of the sliding window and on the polynomial order chosen. By the last equation we approximate each point in the window  by the polynomial defined by its coefficients in . But in fact, only the central point at shall be approximated. so that only the
by the polynomial defined by its coefficients in . But in fact, only the central point at shall be approximated. so that only the  th row vector of the hat matrix is required to calculate the smoothed center point of the sliding window. Let’s call this vector
th row vector of the hat matrix is required to calculate the smoothed center point of the sliding window. Let’s call this vector  . The Savitzky-Golay coefficients correspond to the entries in . Extract the corresponding row vector by multiplying the
. The Savitzky-Golay coefficients correspond to the entries in . Extract the corresponding row vector by multiplying the  -vector
-vector ![\left[0, \dots, 0, 1, 0, \dots, 0 \right]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-edfe34556f29c6a2b170c298f77d9515_l3.png "Rendered by QuickLaTeX.com") with the hat matrix . By the way, the same coefficients you would have also gotten from the first row of the matrix
with the hat matrix . By the way, the same coefficients you would have also gotten from the first row of the matrix  which would require one less matrix multiplication.
which would require one less matrix multiplication.  is also used when it comes to calculating derivatives. The second row of corresponds to coefficients used to calculate the first derivative at the center point. Or more general, the
is also used when it comes to calculating derivatives. The second row of corresponds to coefficients used to calculate the first derivative at the center point. Or more general, the  -th derivative corresponds to the
-th derivative corresponds to the  -th row in scaled by a factor
-th row in scaled by a factor  and divided by
and divided by  (given the spacing between data points is not
(given the spacing between data points is not  ).
).
I guess after so much theory a short example will clarify things a bit.
Example
Say we have a window width of  , so the data points
, so the data points  are equal to
are equal to  . Thus, for a polynomial for degree 2 we can write down the matrix as:
. Thus, for a polynomial for degree 2 we can write down the matrix as:
![\[\mathbf{J} = \begin{bmatrix}1 & -M & M^2 \\1 & -(M-1) & (M-1)^2 \\\vdots & \vdots & \vdots \\1 & M & M^2\end{bmatrix} = \begin{bmatrix}1 & -2 & 4 \\1 & -1 & 1 \\1 & 0 & 0 \\1 & 1 & 1 \\1 & 2 & 4\end{bmatrix} \]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-a1aa9b6e6874ee884ce880b866a2c9b4_l3.png "Rendered by QuickLaTeX.com")
Calculating returns in this example:
![\[\mathbf{H}_{5 \times 5} = \frac{1}{35} \begin{bmatrix}31 & 9 & -3 & -5 & 3 \\9 & 13 & 12 & 6 & -5 \\\mathbf{-3} & \mathbf{12} & \mathbf{17} & \mathbf{12} & \mathbf{-3} \\-5 & 6 & 12 & 13 & 9 \\3 & -5 & -3 & 9 & 31\end{bmatrix} \]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-425d637df28ecc075ddf9dc3d58afce8_l3.png "Rendered by QuickLaTeX.com")
I highlighted the central row vector  in bold. Compare its entries with the entries in table from the beginning and you’ll see the coefficients equivalence.
in bold. Compare its entries with the entries in table from the beginning and you’ll see the coefficients equivalence.
The matrix is in this example:
![\[\mathbf{B}_{3 \times 5} = \frac{1}{35} \begin{bmatrix}-3 & 12 & 17 & 12 & -3 \\-7 & -3.5 & 0 & 3.5 & 7 \\5 & -2.5 & -5 & -2.5 & 5\end{bmatrix} \]](https://dataanalysistools.de/wp-content/ql-cache/quicklatex.com-5283e279284cc6eaebf51520fedcd0e0_l3.png "Rendered by QuickLaTeX.com")
Literature
A. Savitzky and M. J. E. Golay, Smoothing and differentiation of data by simplified least squares procedures, Anal. Chem., vol. 36, pp. 1627–1639, 1964.
Gorry, P. A. General least-squares smoothing and differentiation by the convolution (Savitzky-Golay) method. Anal. Chem. 1990, 62, 570−573.
Schafer, R. W. What is a Savitzky-Golay filter? [Lecture Notes]. IEEE Signal Processing Magazine 2011, 28, 111−117.
Savitzky-Golay Filter article on Wikipedia: https://en.wikipedia.org/wiki/Savitzky%E2%80%93Golay_filter